Design overview¶
This file describes the high level design of Cerise, covering the architecture, functionality,and behaviour of the system. The general principle of operation is to run the standard CWLTool on some remote resource, feeding it the job given to the service by the user. To allow the job to run correctly, input must be staged to the remote resource, and output must be staged back to some location where the user of the service can access it.
As the implementation is not yet complete, this is a description of how I’d like it to eventually be, not of how it currently is (although most pieces are already in place).
Architecture¶
Cerise has a simple architecture.
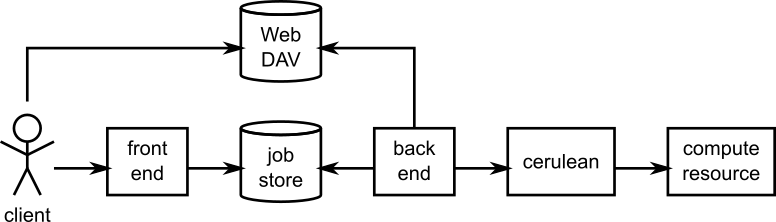
Architecture of Cerise. Arrows show the direction of calls.
The front end of the system is provided by server-side Python bindings for the REST API, as generated by Swagger (which uses connexion). In the middle is the job store, in which the currently known jobs are registered, and which takes care of synchronisation between the front end and the back end. The back end takes care of staging and running jobs, using the Cerulean library to connect to the compute resource.
Functionality¶
The front end is mostly generated code. It takes requests from the client, and calls the job store to add or change jobs, or obtain their current status. (See below under Behaviour.)
The job store is a simple SQLite database that stores the list of jobs that are currently known to the system. It implements the basic create-read-update-delete cycle for jobs. A job in the Job Store holds all the available information about the job, with the exception of the input and output files, which are stored on disk or in a separate WebDAV service.
The back end comprises four components: Local Files, Remote Files, the Job Runner, and the Execution Manager.
The Local Files component manages the local storage area. This local storage area is used for communicating files with the client. Before submitting a job, the client may upload or copy a file to this area, and then pass a file:// URL to the service referring to it. Alternatively, http:// URLs may be used, which LocalFiles can also access. The local storage area may be a directory on a local file system, or a directory on a WebDAV.
Local Files contains functionality for opening input files for staging, creating directories for job output, and publishing job output.
The Remote Files component manages a remote storage area, presumably on the compute resource, or at least accessible from there. This is used for communication with the compute resource. The remote storage area is simply a directory on a file system that is accessible through any of the Cerulean-supported access methods. Inside this directory, Remote Files keeps one directory per job. It will stage input there, and retrieve output from there. Remote Files also contains functionality for interpreting the job’s output, and updating the state of the job based on this.
The Job Runner component contains the functionality for starting jobs on the compute resource, getting the current status (waiting to run, running, done) of remote jobs, and for cancelling them. It does not interpret the result of the job, and cannot tell whether it completed successfully or not, it only knows whether a job is running or not.
The Execution Manager contains the main loop of the back end. It calls the other components to stage in submitted jobs, start jobs that are ready to run, monitor their progress, destage them when done, and cancel or delete them on request.
Behaviour¶
Jobs in Cerise go through a sequence of operations as they are being processed. The behaviour of the system as it processes a job can be described as executing the following state machine:
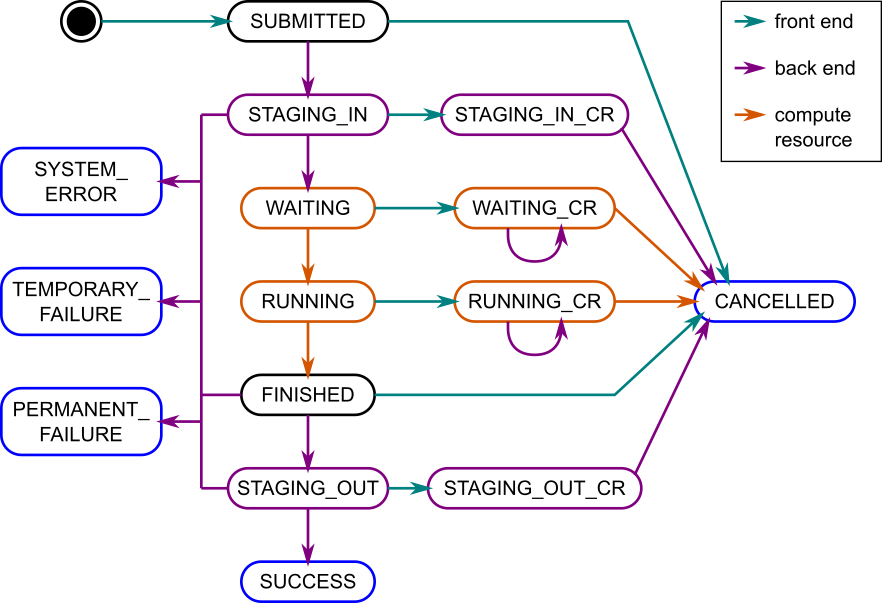
Internal job states and components that act on them. Black and blue states are rest states, blue states are final states, in purple states the back end is active, and in orange states the compute resource is active (and being observed by the back end).
This state machine is not only used to keep track of where a job is in the process of being executed, but also as a way of synchronising between different threads of execution within the service, through atomic state transitions. More on this below.
In total, there are fifteen internal states that a job may be in:
| State | Type | CWL State | Category |
|---|---|---|---|
| SUBMITTED | Rest | Waiting | |
| STAGING_IN | Active | Waiting | |
| WAITING | Remote Active | Waiting | |
| RUNNING | Remote Active | Running | |
| FINISHED | Rest | Running | |
| STAGING_OUT | Active | Running | |
| SUCCESS | Rest | Success | Final |
| STAGING_IN_CR | Active | Waiting | Cancellation pending |
| WAITING_CR | Remote Active | Waiting | Cancellation pending |
| RUNNING_CR | Remote Active | Running | Cancellation pending |
| STAGING_OUT_CR | Active | Running | Cancellation pending |
| CANCELLED | Rest | Cancelled | Final |
| PERMANENT_FAILURE | Rest | PermanentFailure | Final |
| TEMPORARY_FAILURE | Rest | TemporaryFailure | Final |
| SYSTEM_ERROR | Rest | SystemError | Final |
Normal execution¶
When a job is submitted to the system, an entry is added to the job store representing the job, in state SUBMITTED. The job is then moved to the STAGING_IN state, and staging in commences. In general this may take a while, depending on network speeds and data volumes. Once all files are copied, the job is submitted to the remote resource, and the job is moved into the WAITING state.
At some point, resources will become available at the remote compute resource, and the job is started, putting it into the RUNNING state. When it stops running, it moves on to FINISHED, from where the service will move it into STAGING_OUT and start the staging out process. When that is complete, and assuming all went well, the job ends up in stage SUCCESS.
While the job is being processed, the user may request its status via the REST API. The REST API defines a more limited set of states, to which the internal states are mapped (third column in the table). The mapping is such that the Success state signals that the job finished successfully and results are available, while Waiting and Running signal that the user will have to wait a bit longer.
Cancellation¶
If the user submits a cancel request for a job, processing needs to be stopped. How this is to happen depends on the current state of the job. If the state is a Rest state (second column, black and blue in the diagram), then it is not actively being processed, and it can simply be moved to the CANCELLED state.
If the job is in an Active state (purple in the diagram), it is moved to the corresponding _CR state, processing is stopped, and it is then moved to the CANCELLED state (this to synchronise front end and back end, see below). If it is in a Remote Active state (orange in the diagram), it is moved to the corresponding _CR state, and a cancellation request is sent to the compute resource (purple circular arcs). Once the compute resource has stopped the job, it moves into the CANCELLED state.
Note that all activities done by the remote compute resource are observed by the service’s back end, and any state changes are propagated to the service’s job store periodically.
Errors¶
If an error occurs during processing, the job will be in an Active or Remote Active state (since in a Rest state nothing happens, and so nothing can go wrong).
During staging in, in state STAGING_IN, permanent errors may occur if an input file is not available (e.g. due to a mistyped URI). Temporary failures are also possible, e.g. if an http URI returns error 503 Resource Temporarily Unavailable. In this case, staging is aborted, and the job moved to the corresponding error state. If an internal error occurs (which it shouldn’t, but no program is perfect) the job is put into the SYSTEM_ERROR state.
Unsuccessful workflow runs will result in a CWL error of type PermanentFailure or TemporaryFailure, as signalled by the remote CWL runner. Once a job is in the FINISHED state, this output will be examined, and if an error has occurred it will be moved into PERMANENT_FAILURE, or TEMPORARY_FAILURE as appropriate. If the remote CWL runner does not produce usable output, a SYSTEM_ERROR results.
If an error occurs during staging out, in state STAGING_OUT, then like for staging in, the process is aborted and the job moved into an appropriate error state (PERMANENT_FAILURE, TEMPORARY_FAILURE or SYSTEM_ERROR).
Service shutdown¶
The service may be shut down while it is processing jobs. If this happens, then the shutdown process must ensure that running activities are stopped, and that the jobs are put into a state from where processing may recommence when the service is started again. This is achieved as follows:
- For all jobs in the STAGING_IN state, staging is aborted, and the job is moved into the SUBMITTED state.
- For all jobs in the STAGING_OUT state, staging is aborted, and the job is moved into the FINISHED state.
- For all jobs in the STAGING_IN_CR state, staging is aborted, and the job is moved into the CANCELLED state.
- For all jobs in the STAGING_OUT_CR state, staging is aborted, and the job is moved into the CANCELLED state.
Service start-up¶
On service start-up, the jobs database is checked. If the service was shut down cleanly, all jobs will be in a Rest state, and the service may start up as normal and start processing.
If any jobs are found to be in an Active state, they will be moved to the corresponding Rest state as per the shutdown procedure above. If staging is idempotent (and they should be) this should allow the system to continue processing where it left off. Ideally, staging will check whether a file already exists on the target side, and not upload or download it a second time.
If any jobs are in WAITING_CR or RUNNING_CR and are still running, a cancellation request will be sent for them, as the service may have crashed after transitioning the state, but before sending the cancellation request, or the cancellation request may have failed for some other reason.
Multiprocess implementation¶
Since this is a web service, multiple clients may access it concurrently. Staging may take a significant amount of time, during which we would like to be able to service requests. Also, even for a single client, a job submission request should not have to wait for completion of staging in to return. Therefore, staging should be done in the background. Furthermore, the remote compute resource should be polled regularly to update the status of running jobs, so that their results can be staged out shortly after they are done.
The service therefore has a front end, which communicates with the user, and a back end, which does most of the work. In the diagram above, state transitions done by the front end are coloured teal, while the ones done by the back end are coloured purple. State transitions performed by the remote resource are coloured orange. These are observed by the back end, and propagated to the job store periodically, since the remote resource cannot access the job store.
Front end threads¶
Front end threads are responsible for state transitions that are made in response to user input. If a client submits a job, the job is created and put into the SUBMITTED state. If a cancellation request is received, and the job is in a Rest state, it will be moved into CANCELLED by the front-end thread. If it is in an Active state, it is moved into the corresponding _CR state (if not already there). If the job is in a Remote Active state, a cancellation request is sent to the remote resource, and the job is moved into the corresponding _CR state (also, if not already there).
Deletion requests are signalled from the front end to the back end via a separate job property, outside of the job state machine. A cancel operation is done first, then deletion is requested.
Back end threads¶
The back end is responsible for staging and job submission. It operates in a loop, finding a job in the SUBMITTED state, moving it into STAGING_IN, and starting the staging process. If during staging the job is moved into STAGING_IN_CR (by a front-end thread), staging is aborted, and the job is moved to CANCELLED. If a shutdown is signalled, staging is aborted and the job is moved back into SUBMITTED.
The back end also regularly polls the remote compute resource, requesting the status of running jobs. Any jobs in the WAITING state that according to the retrieved information are running, are moved into the RUNNING state. Jobs in WAITING_CR go to RUNNING_CR.
If a job is in a Remote Active state, but is found to no longer be running, then if it was in a Cancellation pending state (named _CR) it is moved to CANCELLED. Otherwise, the output is checked to see if the job was successful, and it is moved into an appropriate error state if it was not. If it was successful, is is put into FINISHED.
If the back end finds a job in the FINISHED state, it checks the result. If the job finished successfully, it moves it to the STAGING_OUT state and begins staging out the results. If during staging the job is moved into STAGING_OUT_CR, staging is aborted and the job is moved to CANCELLED. If a shutdown is signalled, staging is aborted and the job is moved back into FINISHED.
Synchronisation¶
To avoid data corruption, there must be a mechanism that keeps multiple threads from working on the same job at the same time. Also, we can’t have multiple state transitions occurring at the same time and interfering with each other. Thus, there must be some synchronisation mechanism between the threads.
In the Rest states, no processing is done, and any thread can safely move the job to another state as long as the state transitions are atomic. This can be implemented in the form of a try_transition(from_state, to_state) -> bool function. If two threads try to transition a job simultaneously, one from A to B and the other from A to C, one will succeed, while the other will fail because its from_state does not match the current state. (A transactional system with optimistic concurrency control.)
Jobs are moved into Active states (STAGING_IN or STAGING_OUT) by the back end, which subsequently owns it until it moves it into another state. The only exception is that during this process, the job may be moved into STAGING_IN_CR or STAGING_OUT_CR by a front-end thread. Effectively, the state machine functions here as a compare-and-exchange based mutual exclusion mechanism.
Known issues/failure modes¶
If the service crashes or is killed while a job is being staged, and this happens just after submission of the job to the compute resource, but before the transition from STAGING_IN to WAITING, the job will be started again on start-up of the service. This may be undesirable; maybe the service could check as part of error recovery whether the job is already running, or has run anyway.
All synchronisation goes via a single job store component, which means that it may become a bottleneck. However, jobs only spend a fraction of their time in state transitions, jobs are independent of one another, and the total amount of data stored is small (kilobytes per job, at most), so this is unlikely to affect scalability.